How I come up with my instagram captions using Python and Scrapy
Last updated: Jan 22, 2022
Note: This is an article I wrote a while back. Enjoy
Greetings readers! I know that the title is kind of misleading so let me begin with a context. There are days when you click a perfect picture and you want to upload it in instagram, and everyone knows the unwritten rule of any social media — you need to have a caption to match the picture. Now you could go to google or any search engine and search for something that matches the picture but what if you know how to code. You can make your computer do the hard work for you ;)
Now you understand the premise, let me make you clear about what I am going to write in this article. Brainy Quote is the world’s largest quotation site. In Brainy Quote, you search for topics and it’ll give you relevant quotes. And we are going to use python to get the best caption for our picture.
As mentioned in the title, we are going to use python as our scraping language. There are many scraping tools and framework available in python and scrapy is one of the popular ones. Having a basic knowledge of python is helpful, but not strictly required but make sure python 3.6+ is installed in your system (there are lots of tutorials available online) . We will be using other tools which I’ll show how to install as required.
As writing this article, I am on python version 3.9.2. I am using linux for this tutorial. If you are in windows, you might want to install git(https://git-scm.com/downloads) and use its bash to run the commands. You can check your python version by running the following command in the terminal
python -v
I have made a new directory called “brainy_quotes_scrape” where I’ll be working from. Now before starting, we are going to make a virtual environment for this project. Virtual environment in python is python environment such that the python interpreter, libraries and scripts installed into it are isolated from those installed in other virtual environments as well as from the system libraries as well. It is like starting from nothing other than bare python in the environment. This helps us to avoid packages version conflicts for future.
You can create virtual environment as shown below
python -m venv venv
This command python -m venv executes a venv module and create a virtual environment in directory called venv. Now activate virtual environment.
source ./venv/bin/activate (For linux & mac)venv\Scripts\activate.bat (For Windows)
You should see (venv) on left side of your terminal.
Now let’s install scrapy and get started!
Running the above command creates a scrapy project in the same directory. Now we are going to create a basic spider that scrapes data from Brainy Quotes. Open the current directory in your favorite code editor. I am using VS Code for this.pip install Scrapyscrapy startproject brainy_quotes .
scrapy genspider brainy_quotes_spider brainyquotes.com
This commands generates a spider named brainy_quotes_spider and adds the following codes inside ‘brainy_quotes/spiders/brainy_quotes_spider.py’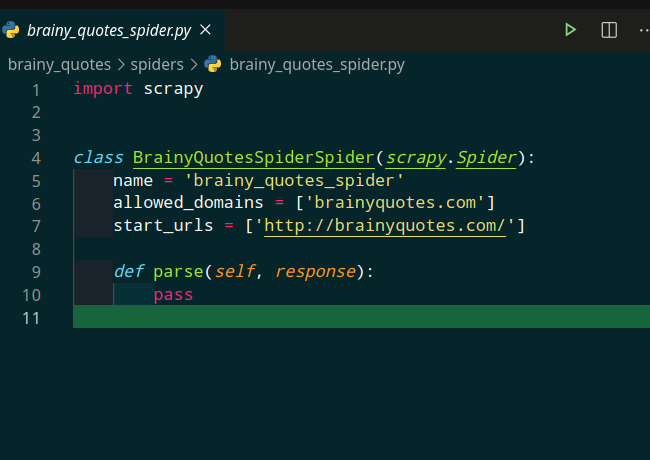
Replace the line 10 with
print('Response',response)
Now run in terminal
scrapy crawl brainy_quotes_spider
You should see some jibberis in your terminal. If you look carefully, you’ll find something of this sort.
And that is the print statement we wrote in line 10. parse method gets the response of from the url we provide. Great. Now let’s look at the url of search page in Brainy Quotes.

As you can see, tree is the keyword we told it to search for. And it separates multiple keywords by ‘+’. This is great news for us.
Now, time to code.
We hae made quite a few changes. We removed start urls and used start_requests method to generate url based on user input keywords. Keywords can be passed as an argument when running the spider command.
scrapy crawl brainy_quotes_spider -a keywords="tree landscapes"
Now for this partkeywords = '+'.join(keywords.split(' '))
This first splits the keywords by space and make it into list of keywords (in example, list contains [‘tree’,’landscapes’] ) and we join it using ‘+’ sign. Running the spider, you can see the url printed out in the terminal.

This is the same url as of the search page.
Time to dig again in Brainy quotes search page. Now to find the quotes in the page, we need to study a little bit about website structure. We need to use Developer Tools or Inspect Element of the browser. I am using firefox for this, but you can use chrome and any chromium based browsers as well.

As we can see, all the quotes are under the div field with an id of quotesList. Let’s search for other components.
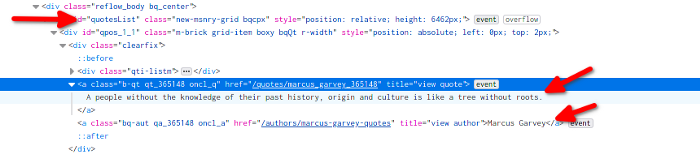
Great! We found our quote as well as the author. If we look at other quotes, it follows the same pattern.
As searching for patterns, we can see that the quote and the author are both <a> tag children of div with class clearfix. So now do let’s this in code.
Look at the parse method. First we get the elements that contains quotes and authors. As we saw previously, we selected all div tags with class clearfix. After that, we iterate over all these divs. For each item, that is the node, we extract the quote text and author name. Notice that we use title attribute present in <a> tag. This makes it easier to extract text and author. Now run the spider using
scrapy crawl brainy_quotes_spider -a keywords="tree landscapes"
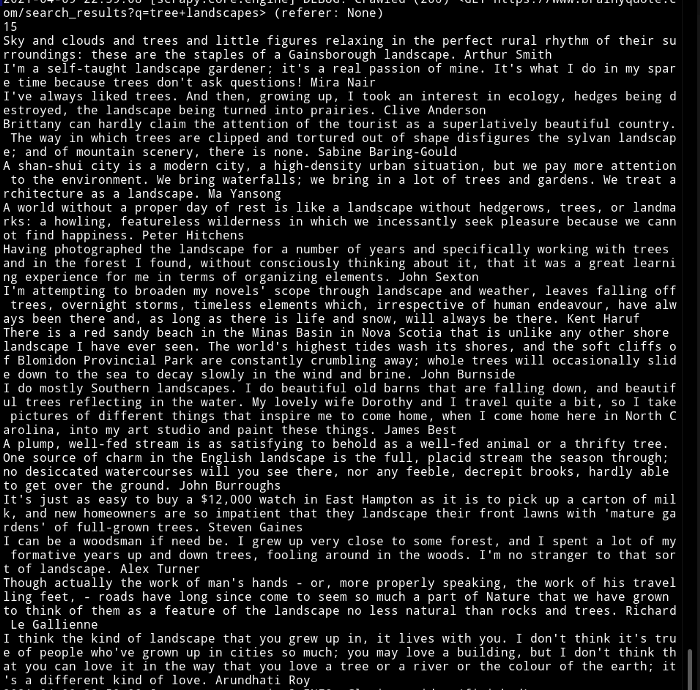
You can see the quotes and author names printed in the terminal.
Now the process to choose instagram caption. Well, I leave that upto the random chance. Yes, that’s right, we are going to pick a random quote and use it.
We used python’s built-in random module to choose one of the quote from the quotesList.
scrapy crawl brainy_quotes_spider -a keywords="tree landscapes"
Running the above code gives this. Your result may vary.
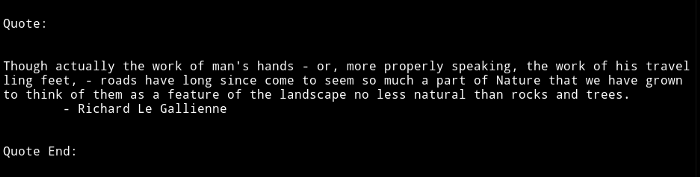
This is how I choose caption for my instagram captions